Guest Post: Fission - Serverless Functions and Workflows with Kubernetes and NATS
Soam Vasani — October 20, 2017
Fission is a framework for “Serverless” Functions or Functions-as-a-Service on Kubernetes. Fission allows you to take a function and easily turn it into a usable service on Kubernetes, without much of a learning curve. Fission supports a variety of source languages and triggers, which are bindings of events to functions.
Fission integrates with the NATS Streaming message queue. Users can map a queue topic to a function using a Fission Message Queue Trigger. Fission then sets up a subscription for that topic, and invokes the function once for each event. The result of the function is then pushed to another topic, also specified by the trigger.
This makes it easy to wire up functions in a reliable and asynchronous manner to systems that generate events (such as Minio, for example).
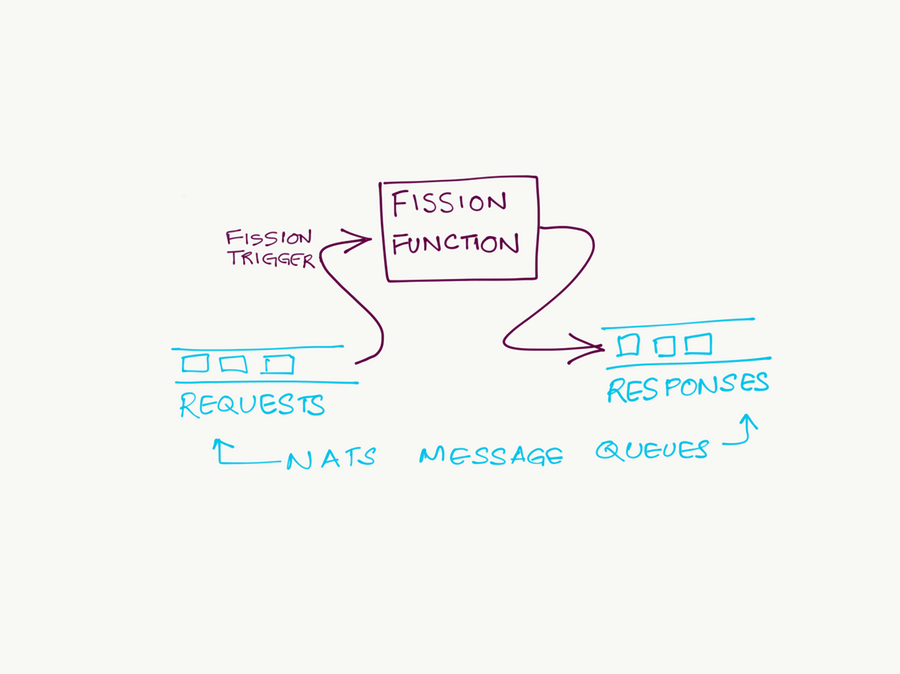
Fission uses the durable version of NATS (NATS Streaming), which supports at-least once delivery. The Fission NATS function trigger does not acknowledge the event to the queue until the function completes successfully — this means if a function fails for any reason during processing of an event, the delivery of that event will be retried.
Event-driven Function Systems
Using the idea of binding functions to message queue topics, you can create very complex event-driven asynchronous application architectures. With Fission and Kubernetes handling the execution of functions, and NATS Streaming providing reliable at-least once messaging, such an architecture can be reliable and run at high performance.
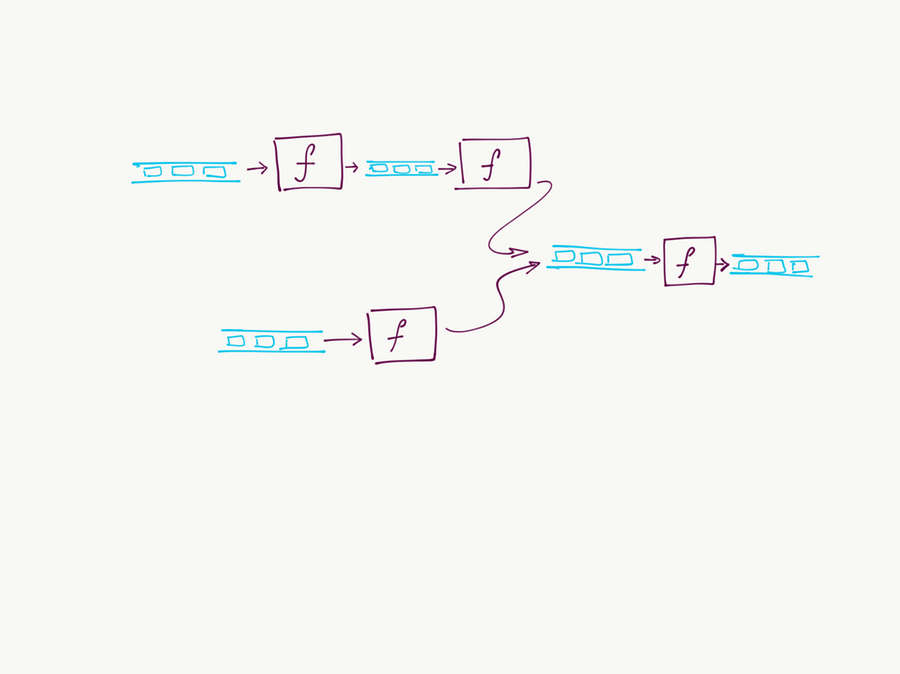
This event-driven architecture has many advantages over a monolith; most importantly it separates the stateful parts of the system into the message queue and allows the more complex compute parts to be stateless.
However, as such an event-driven system grows in size and complexity, it can be hard to maintain. Developers and operators have no visibility into the big picture of the system. Regular tasks like doing an upgrade become really hard problems: operators of the system may not understand how functions interact with each other; there is complex graph of implicit compatibility constraints between functions (and the event data).
Workflows: A “Managed” Event-driven System
To address the limitations of the event-driven approach to function composition, Fission introduced Workflows as a holistic way to model complex event-driven applications.
As a quick intro to what workflows are, think of a flowchart: a sequence of tasks, decisions, loops and so on. A flowchart is a great explanatory tool: it makes the structure of a complex task obvious.
Workflows are like flowcharts for serverless functions, except they’re more powerful. You can compose together functions in sequence or in parallel, send the output of a function to the inputs of another, write if-statements, loops, and even functions that operate on other functions.
Workflows allow you to simply define the control flow and data flow between a set of functions, and have the implementation take care of using the message queue.
Workflows and State
There’s a lot to cover about Workflows: workflow language design, static and dynamic workflow tasks, operational visibility, performance and so on. We’ll dive into these topics in future posts, but in this post we want to focus a bit on the implementation of the workflow engine. In particular, on one area: how we manage state.
At any given time, a workflow execution must keep track of how much of the workflow has completed. It also needs to keep track of the output of functions that have completed, since this output can be used as input to any other function. In other words, it needs to keep track of control flow and data flow.
Event Sourcing: Messages as State
One way for the workflow engine to store its state is as a set of tables in a relational database (or a document in a document database). However, another model of state storage fits better into event-driven designs: Event Sourcing.
Event Sourcing is the idea of modeling state as a series of events that change that state. That way, if you have the whole series of events that occurred, then you can “replay” them to get the final application state. In our case, the workflow engine’s state is the status and output of each task.
The Workflow engine uses NATS Streaming to store these events. By doing so, it remains fully stateless, and in fact can be restarted at any time without any impact to ongoing workflow invocations. Event sourcing also allows the workflow engine’s internal components to be relatively decoupled from each other. And it allows the engine itself to be written in an asynchronous event-driven style, which makes it easier to optimize for performance.
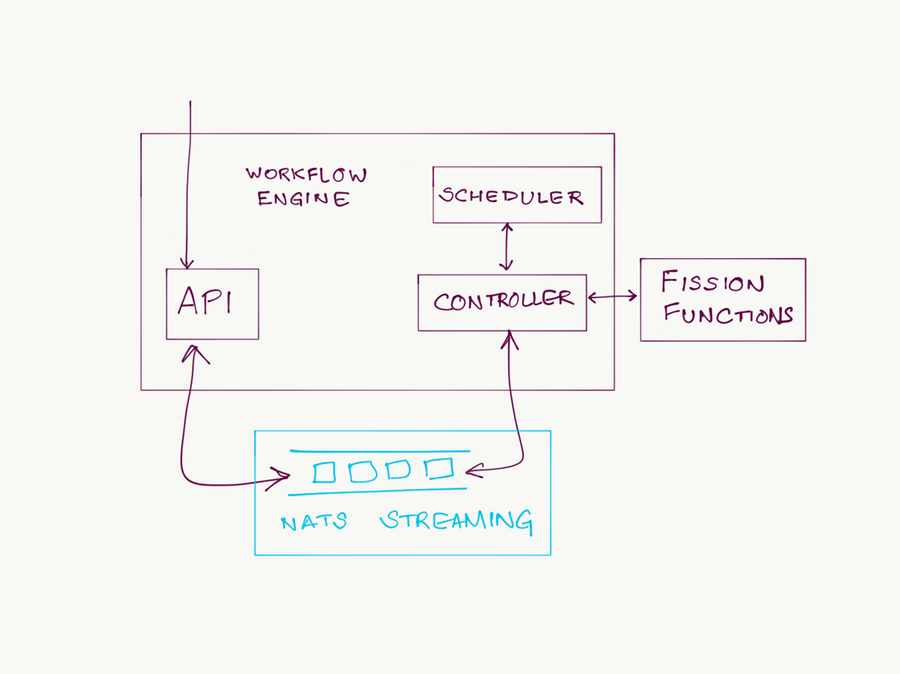
Choosing NATS Streaming as an Event Sourcing Store
An event sourcing application can in theory be written using any kind of store —a filesystem, a database, or a message queue. Message queues provide the closest abstraction level to what we need, since we want to be able to subscribe to events.
We considered several message queues for use with Fission Workflows. We needed a message queue that:
- Is reliable, with at-least-once message delivery, and provides durable storage of messages.
- Has some degree of high performance
- Is relatively simple to operate, and has a “supported” deployment on Kubernetes
We realize that #2 and #3 are very imprecise requirements, but they provide a basis for evaluating the space. Requirement #1 eliminates using in-memory stores like Redis (as awesome as it is, Redis isn’t a great fit for this use case).
NATS Streaming fits these 3 requirements very well. It’s durable, has well-defined at-least-once semantics, has excellent performance characteristics, and is easy to install and operate on Kubernetes.
Conclusion
Fission and NATS Streaming make a great fit for event-driven “serverless” functions on Kubernetes. Using mappings of NATS Streaming topics to function requests and responses allows you to set up systems of asynchronous event-driven functions.
Fission Workflows improves on that by allowing you to specify a set of functions with control flow and data flow. The Fission Workflow engine then executes this workflow while using NATS Streaming to store its state, following an event sourcing pattern.
Learn More
- Fission: fission.io | github | twitter | slack
- Fission Workflows: fission.io/workflows | github
Join us on Wednesday at 10AM Pacific for a webinar about Fission, Workflows and NATS!

Back to Blog