Guest Post: How RapidLoop provides full stack monitoring with OpsDash, built on the Resiliency and Simplicity of NATS.
Mahadevan Ramachandran — August 16, 2017
Here at RapidLoop , we create solutions for operational insight. OpsDash is a server, service, app metric and database monitoring solution that provides intelligent, customizable dashboards and spam-free alerting.
The OpsDash Architecture
The OpsDash SaaS product uses a modern, distributed microservice based architecture. It runs on the Google Cloud Platform and also makes use of GCP services like PubSub and Load Balancers. All backend components of the OpsDash product are written entirely in Go. OpsDash uses a in-house proprietary time series database for storing metric data and PostgreSQL for other, relational data.
All OpsDash components communicate with each other over NATS . A highly available NATS cluster provides the messaging backplane over which components perform request-reply messaging. All inter-component messaging, except for durable queueing (for which PubSub is used), uses NATS.
Why NATS?
While building OpsDash, we evaluated modern solutions to three problems: (1) service discovery (2) failover and (3) load balancing. Apart from working as advertised, we also needed the solutions to be stable, make efficient use of resources, and be low maintenance. We examined many options, that included Consul, etcd, gRPC, HAProxy, keepalived, zeromq and cloud-platform-specific components.
In the end, a NATS-based solution provided certain distinct advantages over others:
- Least number of parts: It was possible to do service discovery and load balancing, as well as support our failover requirements, without additional components. Having a simpler stack improved reliability and maintainability.
- A single communication protocol: It was possible to use only NATS-based messaging entirely and consistently throughout the stack. (Even to talk to the database!)
There were also a few characteristics of NATS that impressed us favorably:
- Stability: The NATS daemon, gnatsd, proved to be stable and extremely resource-efficient.
- Simplicity: The NATS protocol design is commendable for its simplicity and being “just right”. It’s nearly impossible to reduce it anymore, and equally difficult to think of another feature that won’t be superfluous or cause bloat.
- Reliability: With minimal extra code, we could successfully kill and restart each server in a client-NATS-server setup without loss of functionality.
Rather than examining the OpsDash architecture in detail, we’ve picked out three design patterns involving NATS that we hope will be useful takeaways. Here they are:
Pattern: Single Protocol
By having only a single, consistent way of making requests and responses, the complexity of the stack can be kept down and enables more efficient tooling. To be fair, this particular pattern can be implemented by gRPC also (and we’d have chosen gRPC had NATS not solved other problems too).
As a concrete example, if a user tries to rename a dashboard in OpsDash, it goes as an AJAX call to an API backend which then publishes a NATS message with a topic like “maindb”. The message identifies the operation (rename dashboard) and contains the details (the dashboard identifier, new name etc.). The topic “maindb” identifies the microservice.
The service (“maindb”) actually runs on the same box as the Postgres database. Think of “rename-dashboard” as a supercharged stored procedure than can be invoked via NATS.
By talking to Postgres this way, the API backend does not need to link to a PostgreSQL client library, or implement retry or reconnect logic specific to PostgreSQL.
In OpsDash, all components are in Go. All message definitions are fully typed structs. Services are uniquely identified by a name, which is also the NATS topic name. We have a thin wrapper around NATS, used by both clients and services, that handles timeout, retries etc. and adds metrics instrumentation.
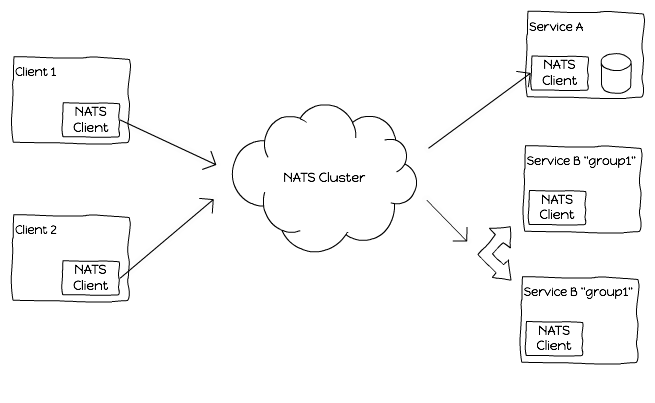
Figure 1: NATS enables single protocol messaging, with service discovery and load balancing
Pattern: Service Discovery
Service discovery with NATS is a no-op in the sense that there is no explicit discovery step. Consumers of a service publish requests, which are replied-to by the service itself. (Again, this is true of any brokered, distributed, real-time messaging system.)
We found that having each service listen on a single NATS topic best suited our use cases. It is also fairly easy to implement a common set of request-response messages across all services (like health or ping).
It is also possible to implement requests like “what services are running” using wildcard subscriptions, or having services listen to a common “meta” topic.
Pattern: Load Balancing
NATS queue groups provide a means of load balancing requests across a group of servers providing the same service. This can be done without any modification to the client code.
Contrast this with a gRPC-based approach, where you’ll have to front a set of gRPC servers with an L4 load balancer (like HAProxy) or a load-balanced HTTP/2 proxy (like Nginx). Since the balancer itself should not become an SPOF, you’ll either have to use a managed solution from the platform-provider, or add redundancy. The latter approach invariably requires going deeper down the rabbit hole, involving more esoteric beasts like keepalived, corosync, ECMP and the like.
With NATS, each service can merely subscribe to a topic with QueueSubscribe instead of a regular Subscribe:
// a regular server
nc.Subscribe("service-name", handler)
// a load-balanced server
nc.QueueSubscribe("service-name", "mygroup", handler)
// a client request, same for either case
nc.Request("service-name", requestData, timeout)
Figure 2: Load balancing with NATS
On the con side, NATS’ load balancing is not sophisticated (random routing). If you need more control or logic for request distribution, you’ll be on your own.
Looking Ahead
We’re quite happy with how NATS has worked out for us so far. Going ahead, we’re improving the tooling around creating and using NATS-based microservices. Have a look at our GitHub project nRPC , which aims generate server and client code for NATS-based microservices based on gRPC service definitions.
We’re also looking forward to seeing more tooling around NATS, and more maturity and adoption in other languages, especially C++ and Python 3. NATS Streaming also looks promising, and we hope to re-evaluate it for our use cases once it supports true high availability.
Oh, and do check out our popular, fun project “ Virtual LAN over NATS ” – just goes to show how versatile NATS can be!
If you would like to learn more about RapidLoop and our solutions, please take a look at our website, watch our GH repos , or follow us on Twitter . We are constantly building new solutions and would welcome input from the Go development community!
Back to Blog