NATS Server 2.9 Release
Byron Ruth — September 16, 2022
The NATS core team and contributors are proud to announce the first release of the 2.9.x series! 🚀
Thank you to the 48(!) people who contributed to this release through GitHub issues, discussions, and pull requests, as well as the hundreds of people in the Slack community who asked questions, presented use cases, and tested early versions of the 2.9 release. ❤️
This release is a milestone for users leveraging JetStream with many improvements and a handful of new features.
The key themes to this release include:
- ⚖️ Increased stability and resilience
- 🌏 Greater scale and mobility
- 🔧 Improved operability and security
The following set of client releases have parity with all 2.9 server features:
- CLI - v0.0.34
- nats.go - v1.1.17
- nats.js - v2.8.0
- nats.deno - v1.8.0
- nats.ws - v1.9.0
- nats.java - v2.16.0
- nats.net - v1.0.1
- nats.rs - async-v0.20.0
The remaining official clients will have support by the end of the month (September 2022).
Background
JetStream was introduced in March 2021, as the successor to NATS Streaming (STAN) which extends NATS to provide at-least-once delivery guarantees and the facilities for exactly-once processing. STAN was designed as a client process that embedded the NATS server. Observing the limitations of this approach both in terms of performance and scalability, JetStream was reimagined as a first-class, embedded subsystem of the NATS server. Since JetStream’s release, adoption has grown significantly to support unique use cases with ever-increasing scale and performance requirements.
JetStream contributes to the overarching vision of NATS which is to be a connective technology, bridging communication between applications in the cloud, devices at the edge, and everything in between. JetStream fills a gap that at-most-once message delivery has, which is “what if a client interested in a message is offline?” For edge devices in particular, losing connectivity is common. JetStream enables these clients to catch-up on messages or re-join a group once they reconnect.
Along with other NATS' capabilities such as decentralized auth , providing multi-tenant identity and authorization management, supercluster and leaf node configurations, supporting cross-geo and hub-and-spoke topologies, and a native WebSocket interface to bridge Web clients to NATS, JetStream lays a new foundation of capabilities including a MQTT interface to bridge existing IoT deployments, as well as key-value and, experimental, object store layers.
All of these capabilities are fully open source , baked into a small, static binary , and with zero dependencies. 🎉
Stability and Resilience
Given NATS vision of being a connective technology, server stability and resiliency are critical.
We can define stability as having predictable behavior, performance, and resource utilization under normal usage, i.e. “it just works”. However, for systems that need to span multiple geographies or need to support edge devices, the system needs to be resilient.
We can define resiliency as being tolerant of atypical situations whether this is spiky traffic, nodes failing, network issues, or slow clients. NATS must still perform under these circumstances using built-in self-healing mechanisms or providing the necessary tooling for an operator to intervene.
A primary focus of 2.9 was to harden and optimize JetStream’s implementation based on real-world usage over the past 18 months since it was released. As a vanity metric, of the net ~15k lines of code added for this release, 67% 📈 of them contributed to improving the test and benchmark suite.
In addition to fixes and optimizations, there are a few notable highlights that improves stability and contributes to NATS' resilience.
Reduced time and bandwidth for replication catch-up
When a server containing stream replicas becomes unavailable or a new server joins the cluster and is assigned one or more replicas, for streams that have a large amount of data in them, it could take a significant amount of time and bandwidth to replicate a full or partial copy of the data. With 2.9, compression is automatically applied to this traffic to optimize this catch-up phase.
A related feature is a new configuration option in the server called
max_outstanding_catchup
which limits the total bytes that are in-flight during stream catch-up. This was introduced to control how much bandwidth should be dedicated during catch-up to guard against saturating and degrading performance of the network.
jetstream {
max_outstanding_catchup: 32MB
}
Improved message distribution for multi-subscription pull consumers
Given two (or more) subscriptions bound to a pull consumers, each subscription sends a fetch request requesting a batch of messages from the server. Prior to 2.9, the requests were serialized and each one would get the full batch of requested messages if available.
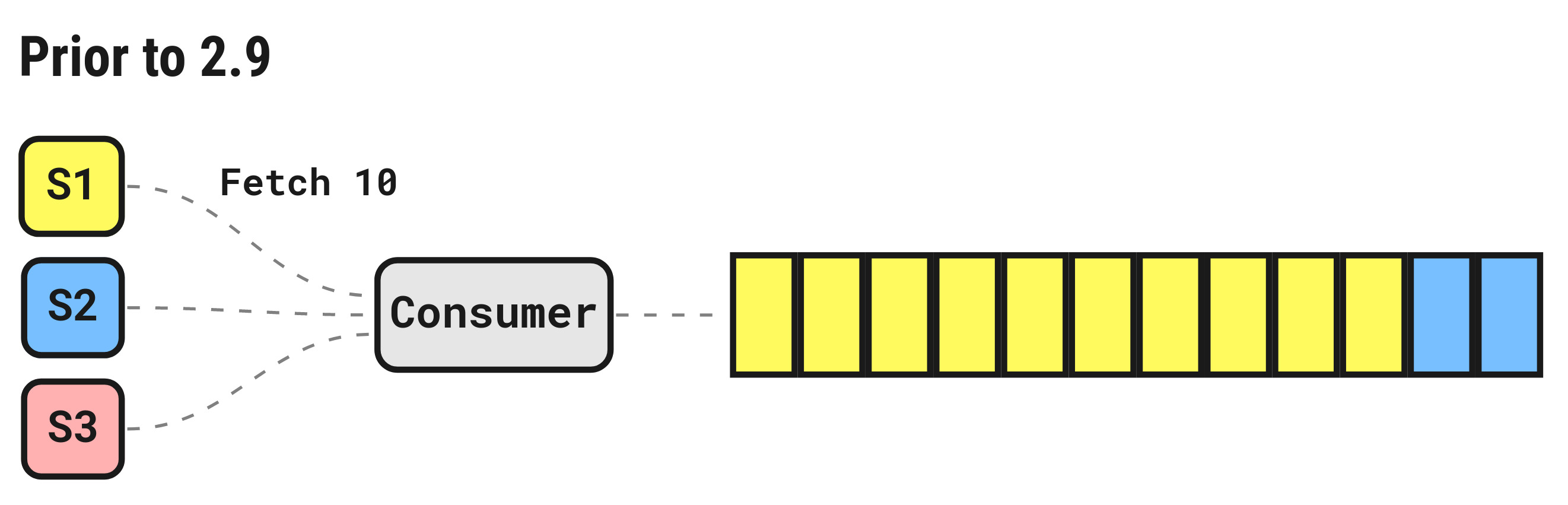
This could result in an imbalanced distribution of messages across available subscriptions. Depending on the processing time of each message, this could significantly decrease throughput.
In 2.9, the distribution algorithm was tweaked to fairly distribute messages across pending fetch requests.
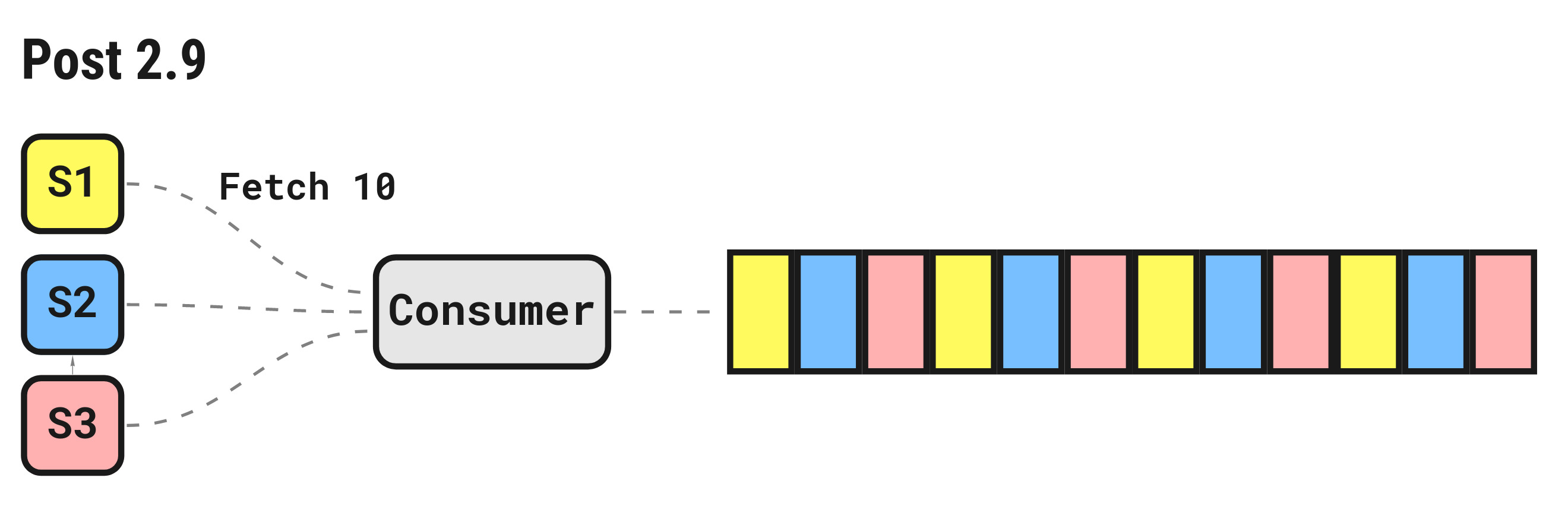
For a set of fetch requests queued on the server, messages will be round-robin distributed until each fetch buffer is full or there are no more pending messages.
Inactive threshold for durable consumers
Consumers can be either ephemeral or durable. By design, an ephemeral consumer is intended to be used for one-off reads/replay of a stream and has a limited lifetime. In the client libraries, ephemerals are often created using one of the convenience methods. For example, in Go, using the
JetStream
interface.
sub, _ := js.SubscribeSync("events.*")
// Do some work...
sub.Unsubscribe()
The client library handles:
- Looking up the stream by pattern matching the subject being subscribed to
- Auto-creating an unnamed consumer (which makes an ephemeral)
- Initializing a subscription and binding it to the consumer
From the server’s perspective, it keeps track of whether at least one subscription is bound to this ephemeral consumer and if the subscription is still active. If/when it detects the subscription is no longer active, it will automatically delete the ephemeral consumer after the
InactiveThreshold
period (which defaults to five seconds).
In contrast, durables are intended to survive process crashes, restarts (client or server), and regardless if there are any active subscriptions. The lifecycle of a durable is expected to be managed by the application/operator.
However, what happens if consumers are being created and not properly cleaned up? Each consumer has a small amount of state associated with it that the server needs to keep track of, replicate, restore, etc. To prevent an evergrowing number of consumers, this consumer configuration can now be applied to durables.
js.AddConsumer("EVENTS", &nats.ConsumerConfig{
Durable: "event-processor",
AckPolicy: nats.AckExplicitPolicy,
InactiveThreshold: time.Hour,
})
In practice, an inactive threshold for a durable should be set to a value that would be highly unlikely the consumer would not have been active in the meantime. In other words, if the consumer is expected to be active regularly every couple minutes, if there is no activity for an hour, that may be a good indicator that the consumer can be auto-deleted.
Memory usage for containerized deployments
As noted above, the NATS server can be deployed in many different environments. An increasingly common one is in containerized environments where, historically, reliable resource management from within a container has been difficult since the Go runtime is unaware of the memory limits set by cgroups in a container and instead base the behavior of the Go GC on the available memory from the host.
Earlier this year,
Go 1.19
was released which introduced a new environment variable called GOMEMLIMIT which better controls when the garbage collector runs in lower-memory resourced environments (see this useful
blog
on the topic).
In containerized environments, such as Kubernetes, it is best practice to set a resource hard limit on containers to prevent overloading the node the container is allocated to. The 2.9 release has been built using Go 1.19 and therefore will respect the GOMEMLIMIT environment variable in the environment you deploy. If you are using the official NATS
helm chart
, this variable can be set automatically by define the
gomemlimit value
.
Scale and Mobility
NATS was designed to scale in multiple dimensions whether the need is high message throughput or geographically distributed nodes to service users or devices.
Combine this with subject-based messaging and intelligent routing of client messages to the closest servicer, NATS provides a global, location transparent connective fabric for messaging, streams, key-value stores, and object storage buckets.
This release brings more capabilities to scale in more dimensions and make data locality more transparent.
Replica and mirror-based direct gets
Streams have supported a GetMsg operation since JetStream was first released. This method is available on the client’s JetStream Manager interface and takes a stream name and the specific sequence number to get a message from the stream. For example, in Go:
js.GetMsg("EVENTS", 29)
With the introduction of the
Key/Value Store
layer which builds upon a stream and relies on subjects for keys, a new API has been exposed directly in the manager API called GetLastMsg which takes the stream name and a subject and returns the last known message for that subject.
js.GetLastMsg("EVENTS", "events.device.15")
With the increasing use cases and potential around the Key/Value API in order to reduce dependencies and infrastructure cost, there has been significant effort in further optimizing get operations, specifically reducing latency, as well as new options to fan-out gets which will further reduce latency and improve scalability.
In 2.9, two new stream configuration options are available: AllowDirect and MirrorDirect. The first allows get operations to be directed to any replica of the stream, not only the leader, while the second allows for (unfiltered)
mirrors
to participate in serving get operations on behalf of the origin stream.
As these options were introduced primarily for Key/Value store, AllowDirect is enabled automatically. For a standard stream, however, it is opt-in.
js.AddStream(&nats.StreamConfig{
Name: "EVENTS",
Subjects: []string{"events.device.*"},
Replicas: 3,
AllowDirect: true,
Placement: &nats.Placement{
Cluster: "us-east",
},
})
To configure a mirror that will participate, create a mirror stream and set the MirrorDirect option.
js.AddStream(&nats.StreamConfig{
Name: "EVENTS-M",
Mirror: &nats.StreamSource{
Name: "EVENTS",
},
MirrorDirect: true,
Placement: &nats.Placement{
Cluster: "us-west",
},
})
Mirrors are of particular interest since they can reside in a different cluster from the origin stream (as shown with the Placement option) to provide data locality and offline access to clients reading from the stream. Client requests will be routed to the closest replica (origin or mirror) that can serve the request. It is also worth a reminder that a Key/Value store is a stream itself, so mirrors can be created for these as well. Given a Key/Value bucket name of FOO, the raw stream name is KV_FOO.
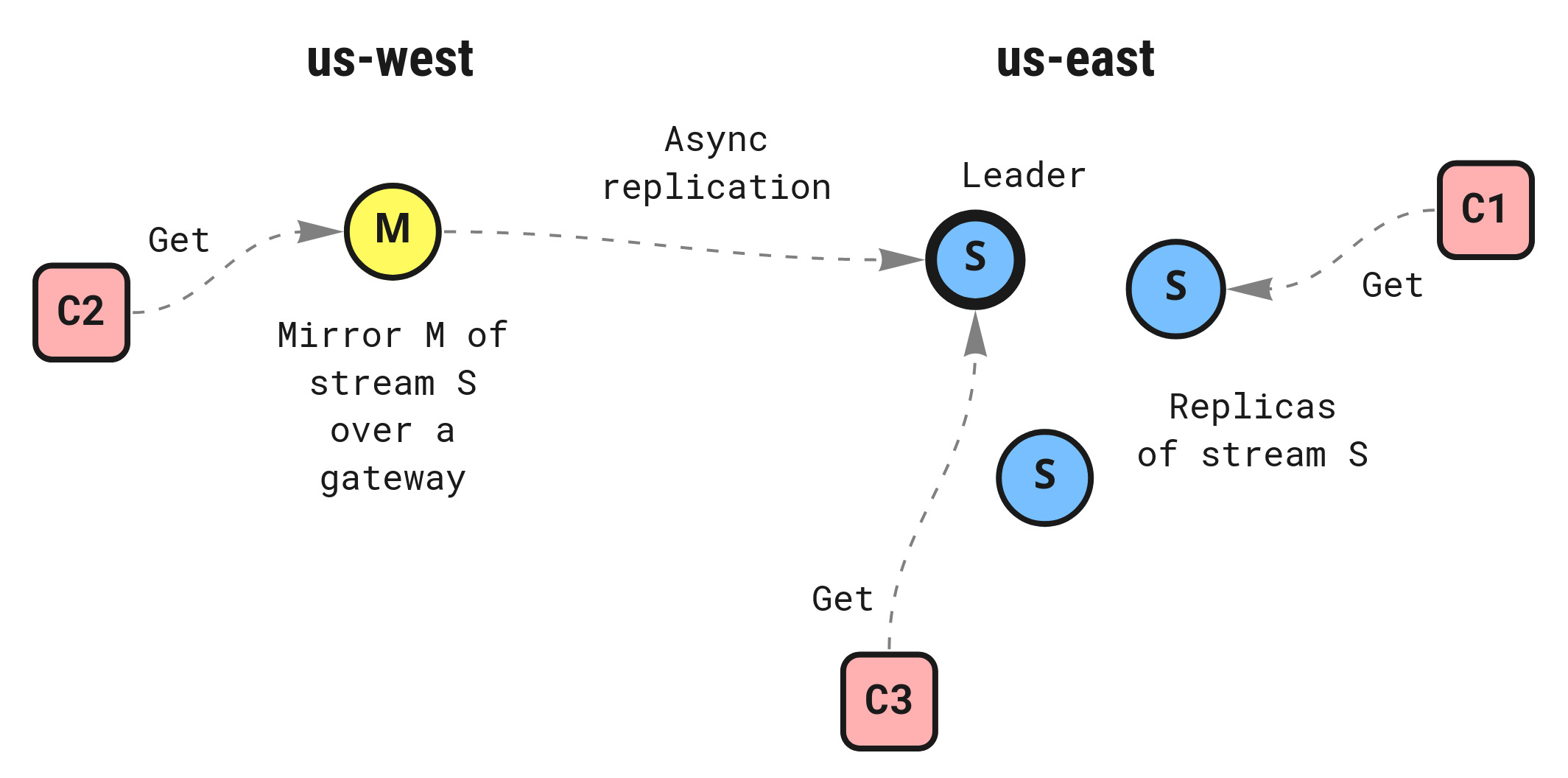
Do note that this introduces a trade-off of reducing pressure on the leader to serve both reads and writes exclusively, however at the risk of getting a stale read if the replica or mirror is not fully caught up. A stale read is much less likely among replicas, but for mirrors that there could be increased latency due to being across regions, or if there are network interruptions.
Each message returned from a direct get call will automatically include a few useful headers:
Nats-Stream- name of the origin stream the message was written toNats-Sequence- sequence number of the message in the origin streamNats-Time-Stamp- timestamp of the message in the origin streamNats-Subject- subject of the message in the origin stream
This provides consistent metadata about the message in the origin stream, no matter where the message is retrieved from.
Stream and key-value message republishing
Message republishing was introduced as an experimental feature in 2.8.3. It has since evolved and matured as an established feature for use cases that want to consume to a stream, but need the scale of core NATS. Combining republish with the more optimized direct get support mentioned above, a new pattern can be implemented to support millions of concurrent subscriptions interested in one or more streams.
So what does republish do and how do you configure it?
For a stream:
js.AddStream(&nats.StreamConfig{
Name: "EVENTS",
RePublish: &nats.RePublish{
Destination: "repub.>",
//Source: ">",
//HeadersOnly: true,
},
})
For a key-value store:
js.CreateKeyValue(&nats.KeyValueConfig{
Bucket: "SNAPSHOTS",
RePublish: &nats.RePublish{
Destination: "repub.>",
},
})
There is a Source and Destination field which supports the
subject mapping
transform. As shown above, the default Source is everything i.e. >. The Destination can be a single token subject or a valid transform from the source. In the above code, a source subject of events.device.15 will be republished as repub.events.device.15.
A new option in this release is HeadersOnly which will omit republishing the data. There are two primary use cases this feature supports:
- Subscribers of republished messages only care about the headers
- Allow subscribers to perform a direct get for the messages they need the data payload (kind of a lazy/deferred data fetch)
Like the direct get capability above, each republished message has the same set of headers injected into it as metadata from the origin stream with an additional one:
Nats-Last-Sequence- sequence number of the prior message for the subject
This header is of particular interest since a client can use it to detect gaps for a given subject. A direct get can then be used to get the previous message for that subject. If there is a larger gap, a one-off ephemeral consumer could be created to backfill additional messages.
Consumer replica, storage, and filter subject change
As of 2.8.3, consumer replicas and forcing memory storage has been supported to prevent inheriting the same configuration as a stream, for example three replicas and file storage.
For use cases that desire a large number of consumers, making them as lightweight as possible can help with scale and performance, such as one replica and having the state in memory.
js.AddConsumer("EVENTS", &nats.ConsumerConfig{
Durable: "processor",
Replicas: 1,
MemoryStorage: true,
})
For applications having consumers created prior to 2.8.3 or consumers created without those settings defined, these configuration options could not be changed.
This release brings the ability to update both Replicas and MemoryStorage after consumer creation.
In addition, the FilterSubject field is now able to be changed after creation.
js.UpdateConsumer("EVENTS", &nats.ConsumerConfig{
Durable: "processor",
Replicas: 1,
MemoryStorage: true,
FilterSubject: "events.eu.*",
})
Server tags and moving streams
Server tags and placement of streams by tag were first introduced in 2.7.4. Each server in a cluster could be configured with zero or more tags indicating some property about them. For example, a cluster deployed in AWS within the us-east-2 region where each node is in a different availability zone.
// Node 1 configuration
server_tags: ["cloud:aws", "region:us-east-2", "az:us-east-2a"]
// Node 2 configuration
server_tags: ["cloud:aws", "region:us-east-2", "az:us-east-2b"]
// Node 3 configuration
server_tags: ["cloud:aws", "region:us-east-2", "az:us-east-2c"]
A stream could then be defined with a placement declaration indicating the subset of nodes in a cluster that the stream replicas should exist on.
js.AddStream(&nats.StreamConfig{
Name: "EVENTS",
Placement: &nats.Placement{
Tags: []string{"cloud:aws", "region:us-east-2"},
},
})
When the server received this request it would determine whether there are a set of servers that have all of these tags. If they have sufficient resources available to host a replica of the stream (assuming an R3 or R5), then that server would be elected.
The unique_tag server config was later introduced in 2.8.0 to declare which tag (by prefix) must be unique with respect to the replicas of a stream. Prior to this addition, it could be possible that all replicas would be placed on the same node (which would defeat the purpose of replication).
jetstream {
unique_tag: "az:"
}
With a server having these additional configurations, placement of replicas for a stream would guarantee to be in different availability zones (being the most common use case).
Stream placement becomes even more flexible by supporting changing the placement declaration in order to transparently move a stream to new servers. This can be done by simply doing js.UpdateStream with a new Placement configuration.
Operability and Security
NATS is multi-faceted infrastructure that can be used in a variety of ways, be it the messaging layer between microservices, leaf nodes deployed on edge devices to ingest sensor data, the backbone for data pipelines and stream processing, etc.
Given how fundamental NATS has become for increasingly large and complex systems, ease of operability and modern security features and practices are crucial.
This release brings a handful improvements further improving the operability and security posture of NATS.
AES-GCM cipher for JetStream file-based encryption
JetStream has had support for encryption at rest since 2.3.0, specifically using the ChaCha20-Poly1305 algorithm. This release adds support for AES-GCM , which may be desired or required for some organizations.
To enable encryption, set the key and the cipher in the jetstream block of the server configuration.
jetstream {
key: $JETSTREAM_KEY
cipher: aes
}
Note: as a best practice, the key should not be inlined in the configuration file. Instead, it can expressed as
variable
using the $ notation which will get interpolated from the environment by default.
Account purge operation
For operators managing accounts, it may be desired to purge all resources associated with an account. A new API available to the system account has been implemented to support this:
$JS.API.ACCOUNT.PURGE.<account>
where <account> is the unique name of the account.
For example, given the following server config with inline accounts :
accounts: {
\$SYS: {
users: [{ user: sys, password: sys }]
}
APP: {
jetstream: true
users: [{ user: app, password: app }]
}
}
Using the CLI, a raw request could be invoked as such:
nats --user sys --password sys \
req '$JS.API.ACCOUNT.PURGE.APP' ''
If using decentralized auth , the account would be the public key.
nats --user sys --password sys \
req '$JS.API.ACCOUNT.PURGE.AAWFSQ7EDAMTCZ2EUZ7B3YPVOF7VFL6ZKUM7IEEMW2IOFXUGTCHMNZEP' ''
New subject mapping functions
NATS supports this concept of subject mapping which, in essence, is a transform of an input subject to an output subject. This can be used for simple remapping, deterministic partitioning, canary deployments, A/B testing, etc. Subject mapping also is used when defining account imports and exports as well as the new republish capability noted above.
In addition, to the standard mapping syntax, e.g. "foo.*.*": "bar.$2.$1" (which changes the prefix and reorders the two wildcard tokens), there are functions including partition() and wildcard(). wildcard() replaces the legacy $x notation, so the previous example could be expressed as "foo.*.*": "bar.{{wildcard(2)}}.{{wildcard(1)}}". This is to disambiguate usage of $, but also be consistent with other functions.
As of 2.9, the following functions are available:
{{wildcard(x)}}- outputs the value of the token for wildcard-token indexx(equivalent to the legacy$xnotation){{partition(x,a,b,c,...)}}- outputs a partition number between0andx-1assigned from a deterministic hashing of the value of wildcard-tokensa,bandc{{split(x,y)}}- splits the value of wildcard-tokenxinto multiple tokens on the presence of charactery{{splitFromLeft(x,y)}}- splits in two the value of wildcard-tokenxatycharacters starting from the left{{splitFromRight(x,y)}}- splits in two the value of wildcard-tokenxatycharacters starting from the right{{sliceFromLeft(x,y)}}- slices into multiple tokens the value of wildcard-tokenx, everyycharacters starting from the left{{sliceFromRight(x,y)}}- slices into multiple tokens the value of wildcard-tokenx, everyycharacters starting from the right
To try out these mappings, check out the nats server mappings command on the CLI.
$ nats server mappings "foo.*.*" "bar.{{wildcard(2)}}.{{wildcard(1)}}" "foo.10.40"
bar.40.10
In this example, first two arguments model the mapping from the source to destination subject and the third argument is an input to test the mapping out against.
Templates for scoped signing keys
Scoped signing keys have been supported since 2.2.0 and is used for simplifying user permission management. An account signing key can be created with pre-defined permissions that a user that is created by the account signing key will inherit. Refer to the documentation link for a full description and short tutorial.
Although scoped signing are very useful and improve security, by limiting the scope of a particular signing key, the permissions that are set may be too rigid in multi-user setups. For example, given two users pam and joe, we may want to allow them to subscribe to their own namespaced subject in order to service requests, e.g. pam.> and joe.>. The permission structure is the same between these users, but they differ in the concrete subjects which are further scoped to some property about that user.
2.9 introduces templated scope signing keys which provides a way to declare the structure within a scope signing key, but utilize basic templating so that each user that is create with the signing key has user-specific subjects.
The following template functions that will expand when a user is created.
{{name()}}- expands to the name of the user, e.g.pam{{subject()}}- expands to the user public nkey value of the user, e.g.UAC...{{account-name()}}- expands to the signing account name, e.g.sales{{account-subject()}}- expands to the account public nkey value, e.g.AXU...{{tag(key)}}- expandskey:valuetags associated with the signing key
For example, given a scoped signing key with a templated --allow-sub subject:
nsc edit signing-key \
--account sales \
--role team-service \
--sk AXUQXKDPOTGUCOCOGDW7HWWVR5WEGF3KYL7EKOEHW2XWRS2PT5AOTRH3 \
--allow-sub "{{account-name()}}.{{tag(team)}}.{{name()}}.>" \
--allow-pub-response
We can create two users in different teams.
nsc add user pam -K team-service --tag team:support
nsc add user joe -K team-service --tag team:leads
The resulting --allow-sub permission per user would be expanded to:
sales.support.pam.>
and
sales.leads.joe.>
Conclusion
The 2.9 release is a milestone release for hardening JetStream and introducing new capabilities and optimizations to push the boundaries of scale and performance.
The NATS team wants to reiterate how appreciative we are for the users who have contributed to this release in one form or another.
Please refer to the granular release notes for the long tail of additions, changes, and fixes as well as PR links on the v2.9.0 release page .
About the Author
Byron Ruth is the Director of Developer Relations at Synadia and a long-time NATS user.
Back to Blog