Performance Profiling of the NATS C Client
Ivan Kozlovic — January 14, 2016
When I was tasked with writing a C client for NATS, I decided to use the excellent Go Client as the model. We were going to provide more Apcera supported clients, and for maintainability sake, it was better that all our clients' implementation follow the same model.
However, before getting the very first alpha release out, I was not happy with the performance results. I decided to use a tool to instrument the code and see where the bottlenecks were.
I knew that publishing - with no subscriber running - was fast, so although we can always improve, the publishing part was not the bottleneck. So I would focus on the subscriber first. There are two threads of interest: one receiving data from the socket and invoking natsConn_processMsg(), the other, the delivery message thread natsSub_deliverMsgs which is responsible for invoking the user callback.
valgrind --tool=callgrind build/nats-subscriber async foo 100000 > res.txt 2>&1 &
build/nats-publisher foo test 100000
When valgrind finishes, it produces a callgrind.out.<pid> file. I load it up with a GUI tool. On my Mac, I use qcachegrind.
Let’s have a look at the message delivery thread:
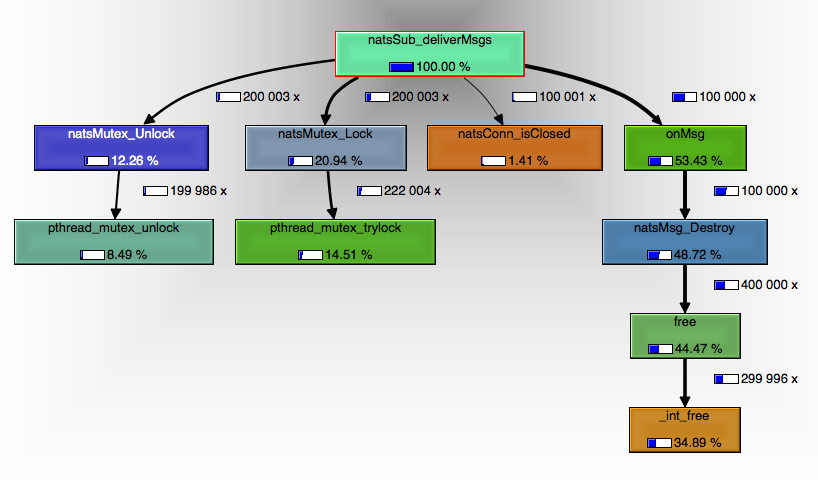
We see that for 100,000 messages received, we lock/unlock 200,000 times. The extra 100,000 lock/unlock were caused by the fact that we were checking for the connection’s close status, which requires the connection lock. This is easy to fix: introduce a boolean in the subscription object itself so that when the connection is closed, this boolean gets updated under the subscription lock. Then, we don’t need the connection lock in the deliver message thread anymore.
Next, although we don’t want the delivery thread spending time in a condition wait, it was surprising to see that it would not even get there (at least not enough to show up in the graph). This is probably due to a very high lock contention with the readLoop thread, which is the one invoking natsConn_processMsg. Let’s have a look at this function now:
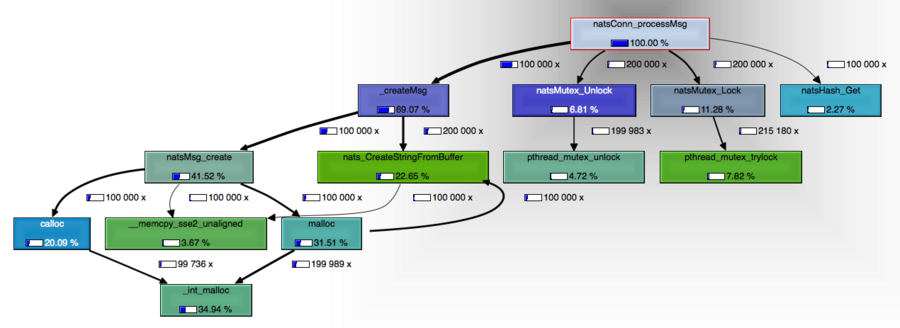
It is not surprising to see that the majority of time spent in this function is the creation of the message. The problem is that this was done under the subscription lock. There was no need for the creation of the message to be done under the subscription lock.
By moving the creation of the message before acquiring the lock, and getting rid of the connection lock in the delivery message thread, I got a 23% boost in performance between the pre and alpha release (see results at the end of this post). The GO Client was later updated with this change .
The last graph also showed something interesting: creating a message required a lot of memory allocations: 1 calloc, 1 malloc, and 2 calls to nats_CreateStringFromBuffer, which, since there is no reply subject, would result in 1 more malloc.
Also, in the delivery message thread, we see that destroying the message is very costly.
Taking all this into account, I was able to optimize further in subsequent releases to a point of doubling the performance between the first and last release (at the time of this writting, verion 1.2.8 ). Creating a message now requires a single malloc, and destroying a message is off-loaded to a dedicated thread.
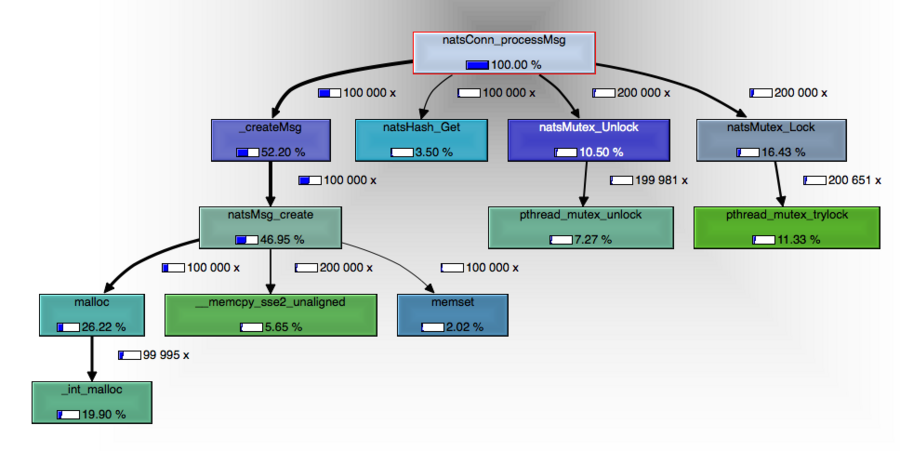
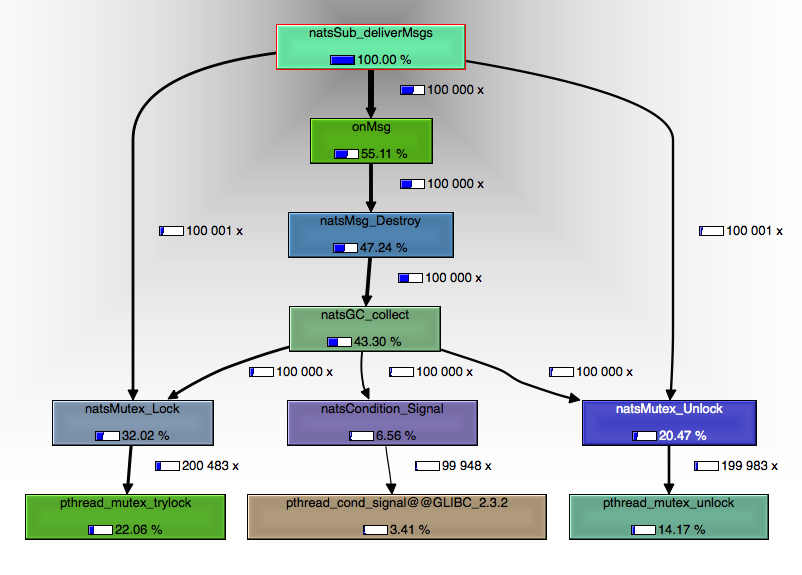
For reference, on my MacBook Pro 2.8 GHz Intel Core i7, running on a Ubuntu 14.04 Docker image, consuming 1,000,000 messages sent on foo with the payload test gives the following results:
pre-alpha release: 1,281,145 msgs/sec
V 0.1.1-alpha : 1,585,618 msgs/sec
V 1.2.8 : 3,065,214 msgs/sec
Happy Profiling!
Download the NATS C Client from github , and browse the API documentation . Let us know what you think, and visit our Community page! Contributors are welcome!
Back to Blog