Guest Post: How Ariane is moving from monolith to microservices with NATS
Mathilde Ffrench — August 16, 2016
Some words about the Ariane project:
While the DevOps trend is reducing application delivery time with automation on any step of the deployment, we still need to reduce the time to understand complex distributed applications:
- We still rely on hand-written technical documentations and diagrams;
- These documentations and diagrams are dispatched across teams (silo effect);
- The documentations and diagrams are also often not up to date (technical debt effect).
Knowledge management is a key factor in reducing silo effect and improving the integration of new team members. And it finally impacts your production KPIs like TTR (Time To Resolution). But :
- When done correctly, it costs a lot of time to produce and maintain the knowledge persistence.
- When not done or done partially, it costs a lot of time to understand your technical environment through reverse-engineering.
The Ariane project is focused on reducing the knowledge production time through real-time diagram automation.
Basically, the Ariane project is a framework : it allows you to develop plugins which will automate the data mining from your runtime and the transformation of this mined data into a bigraph stored in a graph database ( Neo4J ).
Then the user will request the Ariane web server to get the map - or the technical diagram - between some technical points or around a technical point (a technical point could be a server or a process inside a server, for example).
Currently, three open source plugins are available as proof of concept, and we are in the process of developing a NATS plugin:
- The RabbitMQ plugin which allows you to map RabbitMQ clusters, resources and connected applications
- The ProcOS plugin which allows you to map the process running inside your operating system and their connections
- The Docker plugin which allows you to map the Docker containers running inside your operating system and their connections
Below the result map of the Ariane application mapping ( full picture ) :
The system view is a concatenation of the data coming from ProcOS and Docker plugins. The RabbitMQ view has been done with the RabbitMQ plugin.
You can see the Ariane server (process: [29143] java), the ProcOS and Docker plugins (processes: [30432] python3 and [30491] python3) running in the system view. RabbitMQ plugin is running inside the Ariane server.
Scale the monolith: from nanoservices to microservices
The previous Ariane versions have been done as a big Java monolith which is not really sexy with all the last cloud trends but this was a cost saver for the little startup echinopsii :
- It allowed us to focus on the Ariane APIs and functionalities instead of deployment problems.
- It allowed us to quickly show demonstrations to some prospects and at some meetup.
Anyway, monolith doesn’t mean it’s poorly architectured : we followed separation of concern everywhere and Ariane is a combination of many OSGi nanoservices (NOTE: ten years back, the OSGi alliance has coined µservice, but today, I prefer to call them nanoservices to provide a clear distinction with the current containerized and network oriented microservice definition).
So, all these nanoservices are speaking together in the same Java process through memory and clean interfaces. Ariane also provides REST implementation of these services, which allowed us to develop first Ariane Python3 client used by ProcOS and Docker plugins.
But while HTTP and REST APIs are great for human interface, we believe machine to machine communications deserve more efficient network transport:
- We want to reduce transport latency and cost as much as possible. HTTP is slow and more expensive compared to MoM.
- We may need routing accross datacenters and firewalls while installing ProcOS and Docker plugins as local agents on the operating systems to map. The majority of MoM provide easy solutions for that.
Since Ariane 0.8.0 we’re providing a messaging implementation for the Ariane mapping service and since then ProcOS and Docker plugins are able to push the data to the mapping service through messaging bus.
Below a quick diagram describing Ariane 0.8.0 monolith architecture:
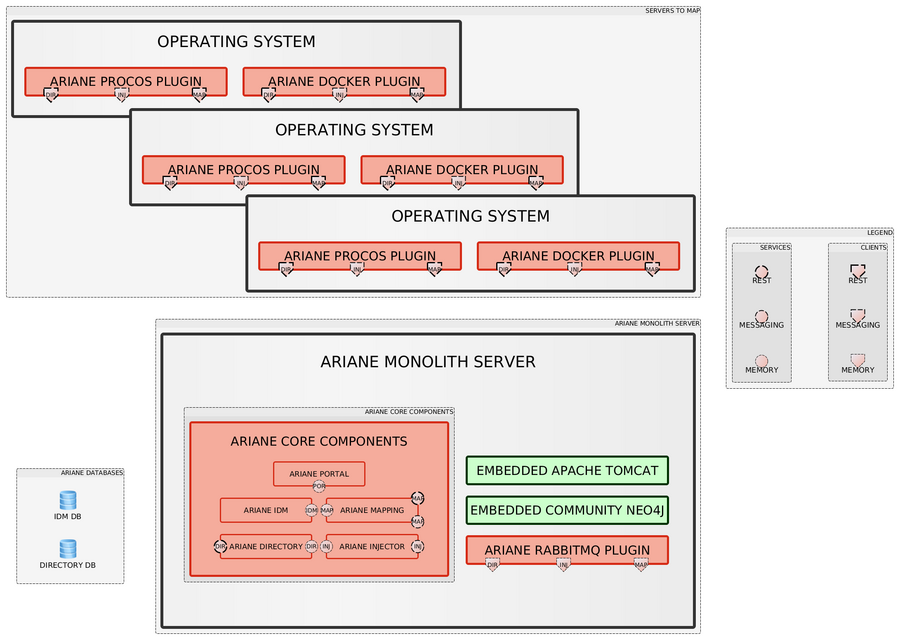
As you can see, the Ariane monolith is embedding lot of stuff from a Tomcat server to a Neo4J database server. To improve the Ariane scalability, we are currently splitting the monolith as described below :
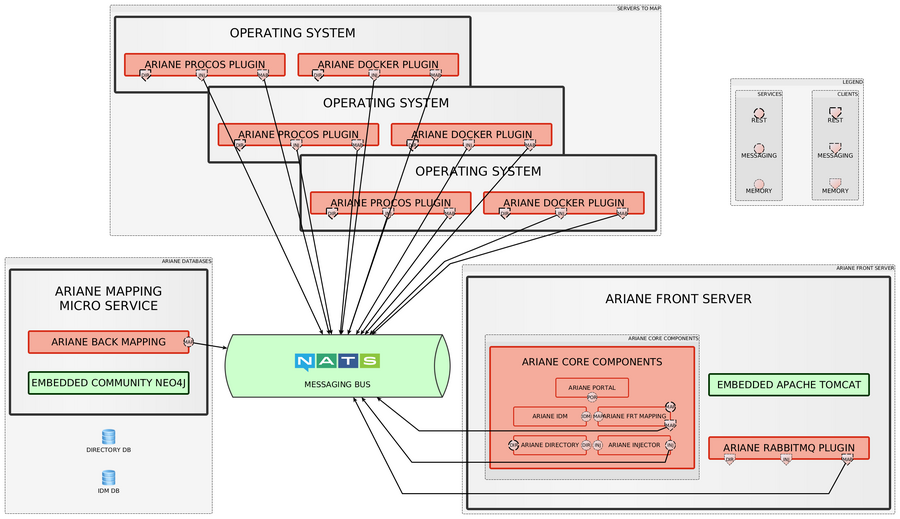
This architecture migration has been done with minimal cost on the plugins side, as they are using the Ariane APIs the same way as before: we just need some changes in the configuration to define which implementation to use (REST or Messaging // Memory or Messaging).
Based on this new architecture:
- We will provide cloud ready docker images and orchestration script templates;
- We will scale the back mapping database with Neo4J enterprise separately to the front web server.
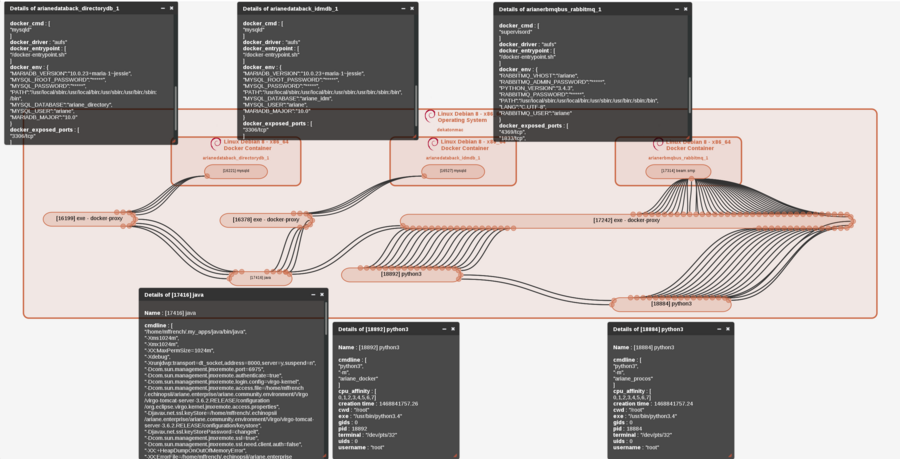
Now, this is how this migration looks like from a system point of view:
before
 (
full picture
)
(
full picture
)
after
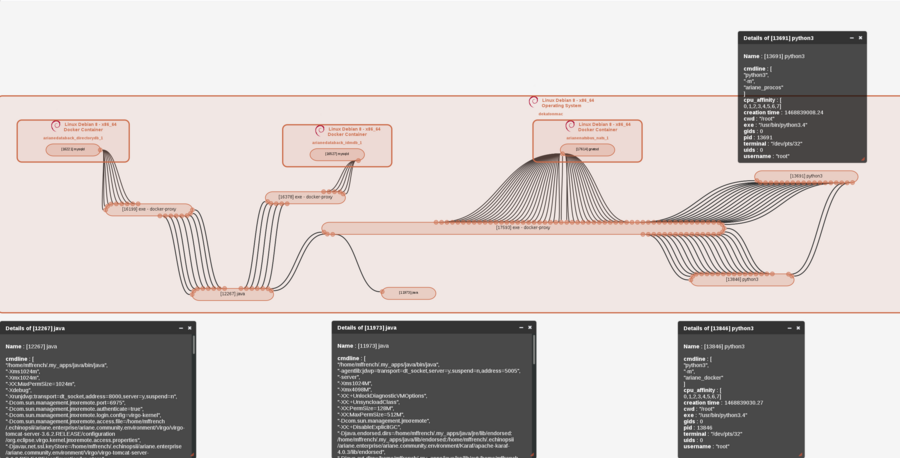 (
full picture
)
(
full picture
)
If you look closely the Ariane maps provided, you’ll notice that :
- A new java process appears: this is the Ariane mapping microservice which embeds the Neo4J community distribution
- We were already using RabbitMQ and we decided to add a NATS implementation for our messaging libraries (Java and Python)
Finally and to resume the reasons why we are using NATS now:
- As we’re migrating data flows from memory to the messaging bus, we have deep concern on the messaging bus latency and throughput: the NATS benchmark scores are impressive ;
- We don’t need messaging persistence/transaction (although NATS now has this via NATS Streaming) in the MoM server: persistence and transactions are managed in the Ariane endpoints;
- We like simplicity: NATS is simple.
Conclusion
Careful readers have noticed some hand made diagrams in this blog post. This is typically the kind of work we love to automate.
As you may understand, the Ariane project is a big trip which makes fun and profit from new graph database technology and which needs an efficient messaging bus to push, as much as possible and as quickly as possible, the data coming from your runtime to a big and unified mapping database.
Ariane is also an open source and inclusive project because there are lots of plugins to write : every day, we’re developing new applications which will raise new problems tomorrow and which will need a fast and deep understanding from OPS and DEVS.
From our point of view, this human understanding of tech is a key point in providing the next step of our evolution : efficient and trusted IA.
The Next Ariane delivery (0.8.1) is scheduled for the end of August 2016. Meanwhile, I’d be happy to read your feedbacks !
Back to Blog