Guest Post: How Clarifai uses NATS and Kubernetes for their Machine Learning Platform
Jack Li — March 8, 2017
Clarifai is a machine learning company which aims to make artificial intelligence accessible to the entire world. Our platform allows users to tap into powerful machine learning algorithms while abstracting away the technical minutiae of how the algorithms work and the infrastructure scaling problems of building AI applications from scratch.
Some of the machine learning algorithms that we run for users can take a few seconds to several minutes to complete. We process the more time-consuming requests asynchronously. One such example is custom training which is a feature that allows customers to generate their own personalized visual models with just the tags they choose to use. It is a feature very few AI companies can provide, and requires sample images to form new neural network connections. As customers increase the complexity of their custom models, it creates large variations on resource utilization and network demand. As we have moved to a high availability Kubernetes architecture, we needed a robust queuing system and retry solution that was fast and reliable. Our development pipeline utilizes CI/CD with Kubernetes, so services restarting in production is quite frequent and normal. This caused some of the asynchronous processes to fail sporadically during these redeployments. In order to better tolerate restarts and make our infrastructure more robust, we wanted to enqueue asynchronous processes in a persistent message queue so that these processes could be retried upon failure.
There are too many choices with queue technology, and we wanted one that plays nice with Kubernetes.
We naturally considered the most popular message queueing services such as Kafka, RabbitMQ and Amazon SQS; however, we ultimately decided to choose NATS Streaming because it was lightweight, written in Golang like our backend, and easily configurable and deployable into our existing Kubernetes infrastructure. NATS Streaming offered at-least-once message delivery which guaranteed that asynchronous processes would be able to survive redeployments. An added benefit of having a message queue data plane was to spearhead the process of breaking up our monolithic backend into smaller microservices which further allowed us to improve our monitoring and logging.
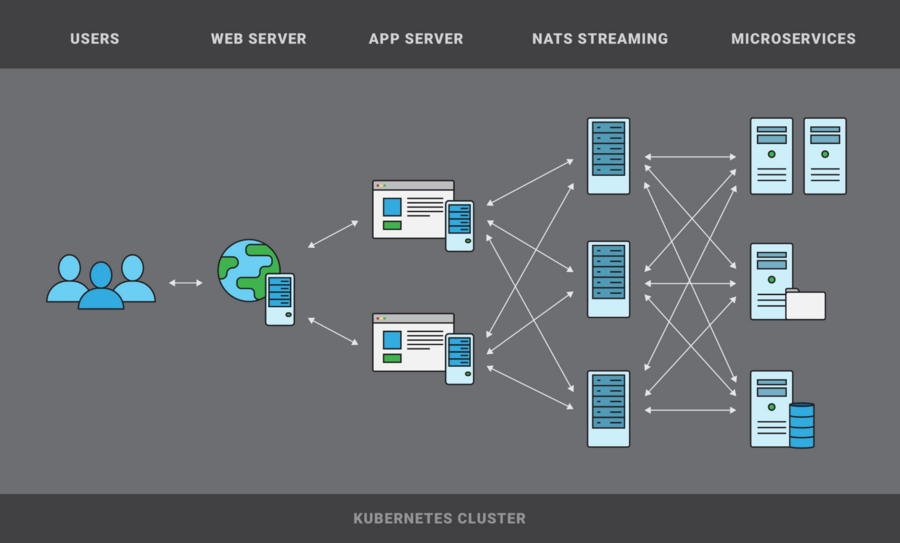
We knew clustering for NATS Streaming was a work in progress when we decided to use NATS, but we wanted high availability in our cluster, so we run three isolated NATS Streaming services backed by Amazon EBS volumes. Each of our microservices that uses NATS connects to all three NATS servers and subscribes to identical subject queue groups for all three. Publishers will choose and publish to a random NATS server and fail if all three NATS servers are unreachable.
One of the issues we ran into early on when using NATS streaming was the lack of sufficient monitoring. Our use case for NATS is non-standard, and we have many subscribers that are “slow” consumers. We wanted the ability to probe how many pending messages there were for each subscription topic which was a feature that NATS supported, but NATS Streaming did not. Luckily, the maintainers of NATS were more than happy to accept the pull request I created to add these subscription metrics into NATS Streaming. Below is a code example of how to get the number of pending messages and bytes for a subscription.
sc, _ := Connect(clusterName, clientName)
// create a slow consumer
slowConsumer := func(m *Msg) {
time.Sleep(10*time.Second)
}
sub, _ := sc.QueueSubscribe("foo", "bar", slowConsumer)
msg := []byte("hello nats")
for i := 0; i < 10; i++ {
sc.Publish("foo", msg)
}
// get pending messages and bytes for the subscription
msgsPending, bytesPending, _ := sub.Pending()
// record the metrics
stats.Count("foo-queue-msgs-pending", msgsPending)
stats.Count("foo-queue-bytes-pending", bytesPending)
In the future, we hope to implement additional features into our NATS Streaming implementation such as additional monitoring and finer granularity and control over the subscriptions and messages inside NATS.
Back to Blog